
Setting up a Ci/Cd Pipeline

A pipeline helps the user to automate the steps in their software delivery process, such as commencing automatic builds and then deploying to Amazon EC2 instances. The user will be using AWS CodePipeline, a service that builds, tests, and deploys the code every time there is a code change, based on the release process models which the user defines. Use CodePipeline to orchestrate each step in the release process. In this article, we will show you how to create a simple pipeline that pulls code from a source repository and automatically deploys it into an Amazon EC2 instance.
AWS CODEPIPELINE
AWS CodePipeline is a continuous delivery service you can use to model, visualize, and automate the steps required to release the user’s software. A developer can quickly model and configure the different stages of a software release process. AWS CodePipeline automates the steps required to release the user’s software changes continuously.
HOW TO GET STARTED WITH AWS CODEPIPELINE
AWS CodePipeline is a continuous delivery service you can use to model, visualize, and automate the steps required to release the user’s software. A developer can quickly model and configure the different stages of a software release process. AWS CodePipeline automates the steps required to release the user’s software changes continuously.
Continuous Delivery and Integration with AWS CodePipeline
AWS CodePipeline is a continuous delivery service that automates the building, testing, and deployment of the user’s software into production.
Continuous delivery is a software development methodology where the release process is automated. Every software change is automatically built, tested, and deployed to production. Before the final push to production, a developer, an automated test, or a business rule decides when the final push should occur. Though every successful software change can be immediately released to production with continuous delivery, not all changes need to be released immediately.
Continuous integration is a software development practice where team members use a version control system and integrate their work frequently to the same location, such as a master branch. Each change is built and verified by means of tests and other verifications in order to detect any integration errors as speedily as possible. Continuous integration is focused on automatically building and testing code, as compared to continuous delivery, which automates the entire software release process up to production.
HOW ACTUALLY THE AWS CODEPIPELINE WORKS?
AWS CodePipeline helps the user to create and manage their release process workflow with pipelines. A pipeline is a workflow construct which describes how software changes go through a release process. A user can create as many pipelines as they need within the limits of AWS and AWS CodePipeline, as described in Limits.
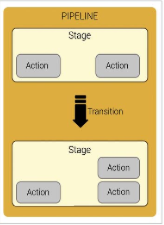
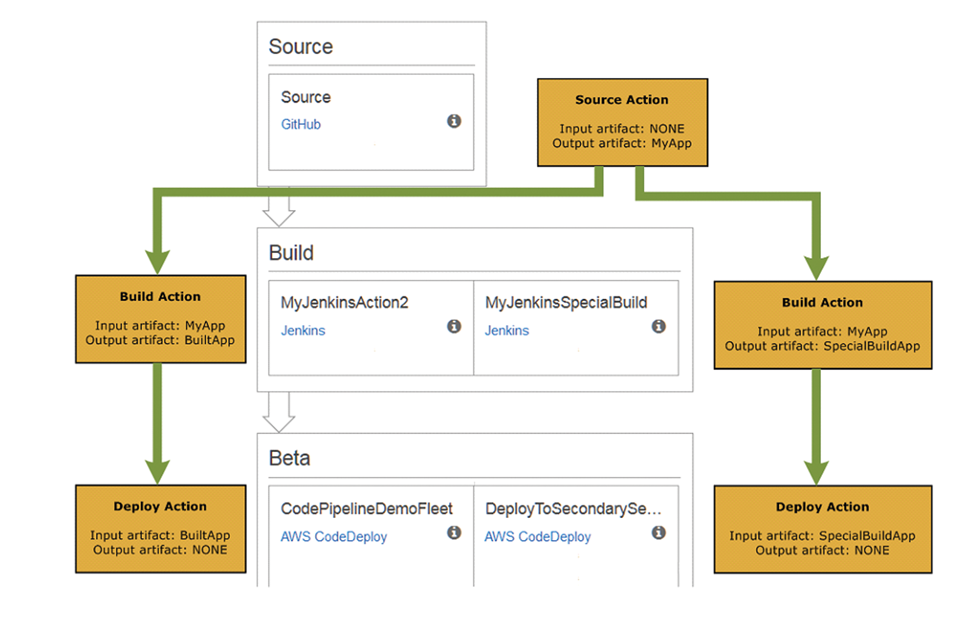
The following diagram and accompanying descriptions introduce you to some of the terms unique to AWS CodePipeline and how these concepts relate to each other:
- When the user creates the first pipeline using the console, AWS CodePipeline creates a single Amazon S3 bucket in the same region as the pipeline to store items for all pipelines in that region associated with the user’s account. Every time the user creates another pipeline within that region in the console, AWS CodePipeline creates a folder in that bucket for that pipeline and uses that folder to store artifacts for the user’s pipeline as the automated release process runs. This bucket is named as codepipeline-region-1234567EXAMPLE, where a region is the AWS region in which the user creates the pipeline, and 1234567EXAMPLE is a ten-digit random number that ensures the bucket name is unique.
- If the user creates a pipeline using the AWS CLI, the user can choose any Amazon S3 bucket to store the artifacts for that pipeline, as long as that bucket is in the same region as the pipeline.
- AWS CodePipeline breaks up the workflow into a series of stages. For instance, there might be a build stage, where the code is built and tests are run. There are also deployment stages, where code updates are deployed to run-time environments. The user can configure multiple parallel deployments to different environments in the same deployment stage. Also, the user can label each stage in the release process for better tracking, control, and reporting.
- Every stage contains at least one action, which is some kind of task performed on the artifact in that stage. Pipeline actions occur in a specified order or in sequence, as determined in the configuration of the stage. For instance, a beta stage might contain a deploy action, which deploys code to one or more staging servers. You can configure a stage with a single action to start, and then add additional actions to that stage as needed.
RUNNING A PIPELINE
A pipeline starts automatically as soon as it is created. The pipeline might go to pause while waiting for the events, such as the start of the next action in a sequence, but it is still running. When the pipeline completes the processing of a revision, it will wait until the next revision occurs in a source location as defined in the pipeline. As soon as a change is identified in a source location, the pipeline will begin running it through its stages and actions.
The user cannot manually stop a pipeline after it has been created, but you can disable transitions between stages to prevent stages and actions from running or adding an approval action to the pipeline to pause the execution until the action is manually approved. To assure a pipeline does not run, the user can also delete a pipeline or edit the actions in a source stage to point to a source location where no changes are being made. If the user deletes a pipeline for this purpose, make sure that a developer should have a copy of its JSON structure first. That way the developer can easily restore the pipeline when they want to re-create it.