What is the main difference between webpack and other build tools like gulp or grunt?
Webpack is a module bundler, though it is quite often used instead of Gulp or Grunt task runners. This advanced tool provides developers with control of spliting the modules, allowing them to adjust builds to particular situations and workaround solutions that don’t function properly out of the box.
Comparing Webpack vs Grunt, the first of those offers more flexibility and advanced functionality for modern front-end projects. It comes with a functional core and can be extended using particular loaders and plugins. Essentially it is used for bundling JavaScript modules with dependencies into files, but for complex JavaScript applications with lots of non-code assets (images, fonts, CSS, etc.) it can provide great benefits.
Talking about Webpack vs Gulp vs Grunt performance, the two latter look into a defined path for files that match your configuration, while the Webpack analyzes the whole project. It looks through all the dependencies, processes them with loaders and produces a bundled JS file.
The dispatcher is AEM’s caching and/or load balancing tool. By using the dispatcher it can also help protect your AEM server from attack since it will be using cached pages. The goal of the dispatcher is to cache as much content as possible, so it does not need to access the layout engine. Load balancing is the practice of distributing computational load of the website across several instances of AEM. The benefits of using the dispatcher as a load balancing tool is so that you gain increased processing power since the dispatcher shares document requests between several instances of AEM, and to have increased fail-safe coverage. This is accomplished by if the dispatcher does not receive responses from an instance, it will automatically relay the request to another instance.
Swagger (Open API Initiative) is a framework for describing the API using a common language that everybody can understand. Think of it as a blueprint for a house. The user can use whatever building materials they like, but they cannot step outside the parameters of the blueprint.
There are other available frameworks that have gained some popularity, such as RAML, API Blueprint, and Summation. But Swagger provides added advantages than just helping to create clear documentation.
Swagger is comprehensible for developers and non-developers: Product managers, partners, and potential clients can have input into the design of API, because they can see it clearly mapped out in this responsive UI.
Swagger is human readable and machine readable: This means that not only can this be shared with the team internally, but the same documentation can be used to automate API-dependent processes.
Swagger is easily adjustable: This makes it great for testing and debugging API glitches.
THE RISE OF DESIGN-FIRST API
With this blueprint in mind, there are two main methods to take benefit of Swagger:
Top-down approach: This means the user using Swagger to design the API before they have written any actual code.
Bottom-up approach: This means the user has already written the code for the API, and the user will be using Swagger to document the API.
In the early days, it was popular for APIs to be created code-first. This is much easier because the user can make adjustments, and it fits nicely into an agile delivery process.
THE SWAGGER TOOL BELT
At the heart of Swagger at its specification, the Swagger spec is the rulebook that regulates API practices. Also, the every other part of Swagger is just a way of appropriating or creating API documentation that works with these rules.
While the spec is the vital spark of the framework, Swagger has been an open source project since its beginning. That means the entire ecosystem has formed around this initiative that not only optimized the rulebook, but built handy tools for its use (SDK generation, dynamic documentation, and server integrations).
TOOLS THAT HELP TO IMPLEMENT SWAGGER
EDITOR
The Swagger editor is a useful tool that addresses the issues. The user can write up the documentation in YAML or JSON and have it automatically compared against the Swagger spec. Any errors are flagged, and alternatives are suggested. When you publish your documentation you can be sure that it’s error-free.
THE USER INTERFACE
One of the reasons that documentation laps up so much of a developer’s time is because it needs to be very organized and navigable. The user have to worry about where to put examples, how to organize the methods, and how much detail has to be provided for each call.
One option for displaying Swagger file is the Swagger-UI. This takes an existing JSON or YAML document and creates interactive documentation.
Awk has had a reputation of being overly complex and difficult to use. Scripting languages such as the UNIX shell and specialty tools such as awk and sed have been a standard part of the UNIX landscape since it became commercially available.
Indeed, both awk and sed are rather peculiar tools/languages. Both be familiar with traditional UNIX “regular expressions”, but not trivial to learn. Both tools seem to offer too many features. Therefore, understanding all the features of awk and sed and confidently applying them can take a while. The user can quickly and efficiently apply these tools once he/she understands their general usefulness and will become familiar with a subset of their most useful features. Explore this article and know more about awk in shell script.
A APROPOS ABOUT REGULAR EXPRESSIONS
Awk was named after its original developers: Aho, Weinberger, and Kernighan. Awk scripts are readily portable across all flavors of UNIX/Linux.
Awk is usually engaged to reprocess structured textual data. It can definitely be used as part of a command-line filter sequence, since by default, it expects its input from the standard input stream (stdin) and writes its output to the standard output stream (stdout). In some of the most operational applications, awk is used in concert with sed complementing each other’s strengths.
The following shell command scans the contents of a file called old file, changing all events of the word “UNIX” to “Linux” and writing the resulting text to a file called new file.
Awk does not change the contents of the original file, it behaves as a stream editor passively writing new content to an output stream. Awk is commonly invoked from a parent shell script covering a grander scope, it can be used directly from the command line to perform a single direct task as just shown.
Although awk has been employed to perform a variety of tasks, it is most suitable for construing and manipulating textual data and generating formatted reports. A distinctive example application for awk is one where a lengthy system log file needs to be examined and summarized into a formatted report. Consider the log files generated by the send mail daemon or the uucp program. These files are usually lengthy, boring, and generally hard on a system administrator’s eyes. An awk script can be employed to parse each entry, produce a set of counts and flag those entries which represent chary activity.
Awk scripts is easy-to-read and are often several pages in length. The awk language offers the typical programming constructs expected in any high-level programming language. It has been defined as an interpreted version of the C language, but although there are comparisons, awk differs from C both semantically and syntactically.
AWK INVOCATION
At least two distinct methods can be used to invoke awk. The first includes the awk script in-line within the command line. The second allows the programmer to save the awk script to a file and denote to it on the command line.
awk ‘{
awk -Fc -f script_file [data-file-list …]
Notice that data-file-list is always optional, since by default awk reads from standard input. As a general rule, it is a good idea to maintain the awk script in a different file if it is of any significant size. The -F option controls the input field-delimiter character. The following are all valid instances of invoking awk at a shell prompt:
If the user acquires a thorough understanding of awk’s behavior, the complexity of the language syntax will not be so great. Awk offers a very well-defined and useful process model. The programmer is able to define groups of actions to occur in sequence before any data processing is performed, while each input record is processed, and after all input data has been processed.
With these groups in mind, the basic syntactical format of any awk script is as follows:
BEGIN { }
{ }
END { }
The code within the BEGIN section is executed by awk before it scans any of its input data. This section can be used to initialize user-defined variables or change the value of a built-in variable. If the user’s script is generating a formatted report, then the user might want to print out a heading in this section. The code within the END section is executed by awk after all of its input data has been processed. Both the END and BEGIN sections are optional in an awk script. The middle section is the implicit main input loop of an awk script. This section must contain at least one explicit action. That action can be as simple as an unconditional print statement. The code in this section is executed each time a record is encountered in the input data set. By default, a record delimiter is a line-feed character. So by default, a record is a single line of text. The programmer can redefine the default value of the record delimiter.
THE VERDICT
Scripting languages and specialty tools that allow fast development have been widely accepted for quite some time. Both awk and sed deserve a spot on any Linux developer’s and administrator’s workbench. Both tools are a standard part of any Linux platform. Together, awk and sed can be used to implement effectively any text filtering application—such as perform repetitive edits to data streams and files. We hope the information provided in this article is useful and inspires you to begin or expand your use of these tools.
Despite the huge number of events JavaScript provides out of the box for a whole horde of scenarios, there will be times when the user wants to fire his/her own events for their certain needs.
There are many reasons for why the user might want to do that. Events provide a level of decoupling between the thing that fires the event and the thing that listen for that event. In the event-driven world that we live in, the DOM elements doesn’t need to be familiar with the inner workings of the code. By relying on events, the user has a great deal of flexibility in changing things around in the UI or in the code without breaking things and doing a lot of clean-up afterwards. This makes the built-in events and custom events created by the user more useful.
To take advantage of this usefulness, JavaScript provides the user with just what they need. The user might have named Custom Event that does all sorts of amazing things, and in this article, we’ll take a detailed look at it.
CREATING EVENTS
The user can use the Event constructor to create an event. The first and most important argument is the name of the event.
The event will not bubble by default. To change the behaviour the user has to pass additional options to the constructor.
const customEvent = new Event(‘custom’, { bubbles: true });
Events such as the above are generally referred as synthetic. The function dispatchEvent used above invokes event handlers synchronously, instead of doing it asynchronously through the event loop.
Just remember that if the user would like to stop the propagation of the events at some point, the user need to add cancellable: true to the event options.
BUILT-IN EVENTS
The user might want to simulate an event, that occurs natively in the browser. The instance of that is the “click” event. Imagine having a checkbox:
The difficulty will occur when the user will try to change its state programmatically, through the JavaScript code:
checkbox.checked = true; // the event wasn’t fired
Running the code above will not cause the event to be fired. The user can easily fix that with a custom event.
const clickEvent = new MouseEvent(‘click’);
checkbox.dispatchEvent(clickEvent); // the event was fired
This code will cause “State was changed” to be displayed in the console.
Just note that due to some implementation changes between browsers, trying to dispatch the same MouseEvent twice might fail.
The code below works fine on Firefox, but on Chrome the second dispatchEvent does not work.
2 checkbox.dispatchEvent(clickEvent); // “State was changed”
checkbox.dispatchEvent(clickEvent); // nothing happens
To ensure that the event is dispatched every time, use a brand new event.
checkbox.dispatchEvent(new MouseEvent(‘click’));
CONCLUSION
In our opinion custom events are just better all around. We do think they require a bit more communication though. The user will probably have to write up some comments somewhere that explain what custom events are fired and when and how to make that easy to discover.
Kubernetes is an excellent tool for handling containerized applications at scale. But as you may know, working with kubernetes is not an easy road, mainly the backend networking implementation. Many developers have met many problems in networking and it costs much time to figure out how it works.
In this article, we want to use the simplest implementation as an example, to explain kubernetes networking works. So, let’s dive deep!
KUBERNETES NETWORKING MODEL
Kubernetes manages a cluster of Linux machines, on each host machine, kubernetes runs any number of Pods, in each Pod there can be any number of containers. User’s application will be running in one of those containers.
For kubernetes, Pod is the least management unit, and all containers inside one Pod shares the same network namespace, which means they have same network interface and can connect each other by using localhost.
KUBERNETES NETWORKING MODEL NECESSITATES
All containers can communicate with all other containers without NAT.
All nodes can communicate with all containers without NAT.
The user can replace all containers to Pods in above requirements, as containers share with Pod network.
Basically it means all Pods should be able to easily communicate with any other Pods in the cluster, even they are in different Hosts, and they recognized each other with their own IP address, just as the underlying Host does not exists. Also the Host should also be able to connect with any Pod with its own IP address, without any address translation.
THE OVERLAY NETWORK
Flannel is created by CoreOS for Kubernetes networking, it can also be used as a general software defined network solution for other purpose.
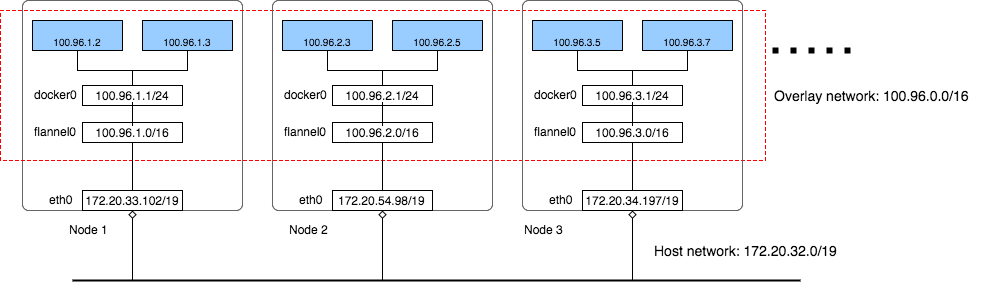
To achieve kubernetes network requirements, create flat network which runs above the host network, this is called overlay network. All containers(Pod) will be assigned one IP address in overlay network, they communicate with each other by calling each other’s IP address directly.
In the above cluster there are three networks:
AWS VPC Network: All instances are in one VPC subnet 172.20.32.0/19. They have been allocated IP addresses in this range, all hosts can connect to each other because they are in same LAN.
Flannel overlay network: Flannel has created another network 100.96.0.0/16, it is a bigger network which can hold 216 (65536) addresses, and it is across all kubernetes nodes, each pod will be assigned one address in this range.
In-Host docker network: Inside each host, flannel assigned a 100.96.x.0/24 network to all pods in this host, it can hold 28 (256) addresses. The Docker bridge interface docker0 will use this network to create new containers.
By the above design, each container has its own IP address, all fall into the overlay subnet 100.96.0.0/16. The containers inside the same host can connect with each other by the Docker bridge docker0. To connect across hosts with other containers in the overlay network, flannel uses kernel route table and UDP encapsulation to attain it.
PACKET COPY AND PERFORMANCE
The newer version of flannel does not recommend to use UDP encapsulation for production, it should be only used for debugging and testing purpose. One reason is the performance.
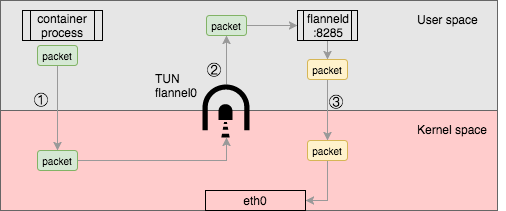
Though the flannel0 TUN device provides a simple way to get and send packet through the kernel, it has a performance penalty, the packet has to be copied back and forth from the user space to kernel space.
as the above, from the original container process send packet, it has to be copied three times between user space and kernel space, this will upsurge network overhead in a significant way.
THE VERDICT
Flannel is one of the simplest implementation of kubernetes network model. It uses the standing Docker bridge network and an extra Tun device with a daemon process to do UDP encapsulation. We hope this article helps you to understand the fundamentals of kuberentes networking, with this information you can start exploring the more interesting realm of kubernetes networking.
All content campaigns begin with the same thing “Keyword Research”.
And there is a reason for this. Targeting keywords will lead to long-term and, probably, short-term organic search traffic for your website.
80% of SEOs and marketers do keyword research in a wrong manner. They plug in a main keyword into Google’s Keyword Planner, download the results, and then start sorting through them in a spreadsheet.
But the fact is that, thousands of other marketers and SEOs have already searched that exact same keyword. Unless the user is very fortunate, he/she won’t find anything similar to a low-competition keyword to target.
Now, if you have a site with the authority of Quick Sprout that is not a big deal. But if the user is working with a less authoritative domain, or a brand new one, then the user need to find realistic keywords to rank for.
The keyword planner only shows a very small portion of keywords which the user can target. If you can find hidden keywords that have a large search volume, but less competition, the organic search traffic will grow rapidly.
In this article we are going to walk you through some of the modern keyword research methods that you can use to uncover keywords that have not been targeted by hundreds or thousands of your competitors.
Focus on topics, not just keywords
Over the years, Google have implemented a series of algorithm changes and websites that exclusively rely on the old-school keyword strategy took huge hits. The global SEO community believes that an effective keyword research is now an amalgamation of the old school way and a new school strategy called ‘concept-based targeting’. The classic way of selecting keywords rely on search volume, while the new school concept emphases on topics and search intent.
For instance:
Old-school method
1. Best electric kettle
2. Electric kettle on sale
Modern method
1. What to look for in an electric kettle
2. How to choose an electric kettle
A combination of both techniques will produce better traffic results. The result of having keywords based on search intent with the keywords based on search volume benefits both the search engine and the user.
Use a reliable keyword research tool
Google Keyword Planner can be little scary for beginners. It is a go-to for SEO professionals but we suggest using a newer keyword tool called ‘Ubersuggest’. It does the same job, but with more advantages and it has a beginner-friendly design.
Here is how to use Ubersuggest to kick start the best keyword research strategies. It will help the user to start mapping out the keywords fast:
1.Key in your ‘seed keyword’:
The user seed keyword is the base or foundation keyword for SEO. Let’s say the user is a distributor of various types and prices of an electric cookers. Then, the user seed keyword is ‘electric cooker’.
Using Ubersuggest, type in the ‘seed keyword’ and filter according to target geography and language. The tool will give its collected data from Google Keyword Planner and Google Suggest, which is very handy, because if the user is only using the former, it will only show the keywords from its database, and the user will have to open another tab to be able to see keywords from the latter.
Google’s Voice Search and Natural Language Search:
One of the developments in Google search that SEO professionals are keeping an eye on is Google voice search and natural language search.
Voice searches make up 20% of mobile voice queries and natural language is taking over search queries. To meet the users evolving search engine use, Google was driven to produce answer boxes and Knowledge Graph panels.
For instance, before, people used to type ‘best jasmine tea’, but now it’s as specific as ‘Is there a jasmine tea shop near me?’
These question-based keyword searches are a vital addition to the users’ keywords list. The user can group these into long-tail keywords for their SEO content marketing strategy.
Conclusion
Doing keyword research does not always have to be time-consuming and painful. Once the keywords sorted, the user will be in a better position to start creating quality content and marketing materials. Have you used any of these strategies before in your keyword research strategies? Which one worked best for you? Let us know!
What is de-normalization in SQL database administration? Give examples?
De-normalization is used to optimize the readability and performance of the database by adding redundant data. It covers the inefficiencies in the relational database software.
De-normalization logical data design tend to improve the query responses by creating rules in the database which are called as constraints.
Examples include the following :
Materialized views for implementation purpose such as.
Storing the count of “many” objects in one-to-many relationship.
Linking attribute of one relation with other relations.
To improve the performance and scalability of web applications.