The Java Servlet API lets you define HTTP-specific classes. A servlet class extends the capabilities of servers that host applications that are accessed by way of a request-response programming model. Although servlets can respond to any type of request, they are commonly used to extend the applications hosted by web servers. For instance, you might use a servlet to get the text input from an online form and print it back to the screen in an HTML page and format, or you might use a different servlet to write the data to a file or database instead. A servlet runs on the server side — without an application GUI or HTML user interface (UI) of its own. Java Servlet extensions make many web applications possible.
What is the difference between traditional Waterfall model and Agile testing?
There are several ways to develop software, two of the most prominent methods being waterfall and Agile.
Waterfall basically is a sequential model where software development is segregated into a sequence of pre -defined phases – including feasibility, planning, design, build, test, production, and support. On the other hand, Agile testing follows a linear sequential approach while providing flexibility for changing project requirements.
Why agile is more adapted is because you can always track your development and you can make changes if it is needed.
What is Product backlog & Sprint Backlog in Agile?
The sprint backlog is a list of tasks identified by the Scrum team to be completed during the Scrum sprint. During the sprint planning meeting, the team selects some number of product backlog items, usually in the form of user stories, and identifies the tasks necessary to complete each user story.
In today’s world, all the major government organizations and financial firms pressure upon the issue cyber security. Sensitive data of the organizations and those keep largely public data, has been the target of some of the most notorious hackers of the world. Manipulation of, data, theft of data, leaking of company secrets, and shutting down services, are some of the many things that hackers have the license to do once they gain access to a system. So, let’s dive deep in and take a look at the 5 most dangerous cyber security vulnerabilities that are exploited by hackers.
INJECTION VULNERABILITIES
Injection vulnerabilities will occur when an application sends untrusted data to an interpreter. Injection flaws are very common and affect a wide range of solutions. The most popular injection vulnerabilities affect SQL, LDAP, XPath, XML parsers, and program arguments. The injection flaws are quite easy to discover by analyzing the code, but it’s hard to find during the testing sessions when systems are already deployed in production environments.
Possible consequences of a cyber-attack that exploits an Injection flaw are data loss and consequent exposure of sensitive data, lack of accountability, or denial of access. An attacker could run an Injection attack to completely compromise the target system and gain control on it.
The business impact of an injection attack could be vivid, especially when the hacker compromise legacy systems and access internal data.
The vulnerability has been in existence for several decades and it is related to the way bash handles specially formatted environment variables, namely exported shell functions. To run an arbitrary code on affected systems, it is necessary to assign a function to a variable, trailing code in the function definition will be executed. The critical Bash Bug vulnerability affects versions of GNU Bash which ranges from 1.14 to 4.3, a threat actor could exploit it to execute shell commands remotely on a targeted machine using specifically crafted variables.
BUFFER OVERFLOWS
A buffer overflow vulnerability condition comes to existence when an application attempts to put more data in a buffer than it can handle. Writing outside the space assigned to buffer allows an attacker to overwrite the content of adjacent memory blocks causing data corruption or crashes the program. Buffer overflow attacks are quite routine and very hard to discover, while compared to the injection attacks they are harder to exploit. The hackers need to know the memory management of the targeted application to alter their content to run the attack.
In an attack scenario, the attacker sends the data to a application that stores in an undersized stack buffer, causing the overwriting of information on the call stack, including the function’s return pointer. In this manner, the attacker will able to run their own malicious code once a legitimate function is completed and the control is transferred to the exploited code which contains in the attacker’s data. There are many types of buffer overflow, but the most popular are the Heap buffer overflow and the Format string attack. Buffer overflow attacks are dangerous, they can target desktop applications, web servers, and web applications.
SENSITIVE DATE EXPOSURE
The most dangerous and the most common vulnerability is sensitive data exposure, it results in calamitous losses for an organization. Sensitive data exposure occurs every time a threat actor gains access to the user sensitive data. Data can be stored in the system or transmitted between two entities, in every case a sensitive data exposure flaw occurs when sensitive data lack of sufficient protection. Attackers, therefore, use this vulnerability to inflict as much damage as possible. The targeted data can be stolen when it is resting in the system, in an exchange transit or in a backup store. Malware is used by hackers when the data is in the system and cryptography techniques when it is in exchange transit.
BROKEN AUTHENTICATION AND SESSION MANAGEMENT
The exploitation of a broken Authentication and Session Management flaw occurs when an attacker uses leaks or flaws in the authentication or session management procedures to imitate other users.
This kind of attack is very common; many hacker’s groups has exploited these flaws to access victim’s accounts for cyber surveillance or to steal the information that could advantage their crime activities.
SECURITY MISCONFIGURATION
We consider this category of vulnerability as the most common and dangerous. It is quite easy to discover. Below are some examples of security misconfiguration flaws:
Running outdated software.
Applications and products running in production in debug mode or that still include debugging modules.
Running inessential services on the system.
Default keys and passwords.
Usage of default accounts.
The exploitation of one of the above scenarios could allow an attacker to compromise a system. Security misconfiguration can occur at every level of an application stack. An attacker can discover the target which is being used in an outdated software or flawed database management systems. This kind of vulnerabilities could have a severe impact for the new paradigm of the Internet of Things.
CONCLUSION
Cyber security is something which is quite an important issue. In this article, we tried to make you aware of some of the most common and dangerous vulnerabilities. Knowing at the initial step is better than knowing it lately, and with this article, we aim to help you in your initial step.
AWS Lambda is a compute service that lets the user to run the code without provisioning or managing servers. AWS Lambda executes the code only when it is needed and scales automatically. The user pays only for the compute time that they consume – there is no charge when the user doesn’t run the code. With AWS Lambda, one can run code virtually for any type of application or backend services. AWS Lambda runs the code on a high-availability compute infrastructure and performs all the administration of the compute resources, such as server and operating system maintenance, capacity provisioning and automatic scaling, code monitoring, and logging. The user need to do is to supply the code in one of the languages that AWS Lambda supports (such as Node.js, Java, C#, and Python).
The user can use AWS Lambda to run the code in response to events, such as changes to data in an Amazon S3 bucket or an Amazon DynamoDB table to run the code in response to HTTP requests using Amazon API Gateway or to invoke the user’s code using API calls made using AWS SDKs. With the above capabilities, the user can use Lambda to easily build data processing triggers for AWS services like Amazon S3 and Amazon DynamoDB process streaming the data which is stored in Amazon Kinesis or the user can create their own back end which operates at AWS scale, performance, and security.
AWS LAMBDA– RUNS JAVA CODE IN RESPONSE TO EVENTS
Many of the AWS users are using AWS Lambda to build clean and straightforward applications which handles image and document uploads, process log files from AWS CloudTrail, and handles the data which is streamed from Amazon Kinesis, and so forth. With the newly launched synchronous invocation capability, Lambda is becoming the most favourite choice for building mobile, web, and IoT backends.
LAMBDA FUNCTION IN JAVA
AWS Lambda has become even more useful by giving the ability to write the user’s Lambda functions in Java.
The user’s code can make use of Java 8 features along with any desired Java libraries. The user can also use the AWS SDK for Java to make calls to the AWS APIs.
AWS is providing two libraries specific to Lambda: aws-lambda-java-core with interfaces for Lambda function handlers and the context object, and aws-lambda-java-events containing type definitions for AWS event sources (Amazon Simple Storage Service (S3), Amazon Simple Notification Service (SNS), Amazon DynamoDB, Amazon Kinesis, and Amazon Cognito). User can author their Lambda functions in one of the two ways. Firstly, they can use a high-level model that uses input and output objects:
public lambdaHandler( input, Context context) throws IOException;
public lambdaHandler( input) throws IOException;
If the user does not want to use POJOs or if Lambda’s serialization model does not meet the user’s needs, they can use the Stream model. This is a bit lower-level:
public void lambdaHandler(InputStream input, OutputStream output, Context context)
throws IOException;
The class in which the Lambda function is defined should include a public zero-argument constructor, or to define the handler method as static. Alternatively, the user can also implement one of the handler interfaces(RequestHandler::handleRequest or RequestStreamHandler::handleRequest) which is available within the Lambda core Java library.
PACKAGING, DEPLOYING, AND UPLOADING
User can continue to use their existing development tools. In order to prepare their compiled code with Lambda, user must create a ZIP or JAR file that contains their compiled code (CLASS files) and any desired JAR files. The handler functions should be stored in the usual Java directory structure and the JAR files must be inside a lib subdirectory. In order to make this process easy, AWS has published build approaches using popular Java deployment tools such as Maven and Gradle.
Specify a runtime of “java8” when the user uploads their ZIP file. If they implement one of the handler interfaces, then they have to provide the class name. Otherwise, they have to provide the fully qualified method reference (e.g. com.mypackage.LambdaHandler::functionHandler).
A pipeline helps the user to automate the steps in their software delivery process, such as commencing automatic builds and then deploying to Amazon EC2 instances. The user will be using AWS CodePipeline, a service that builds, tests, and deploys the code every time there is a code change, based on the release process models which the user defines. Use CodePipeline to orchestrate each step in the release process. In this article, we will show you how to create a simple pipeline that pulls code from a source repository and automatically deploys it into an Amazon EC2 instance.
AWS CODEPIPELINE
AWS CodePipeline is a continuous delivery service you can use to model, visualize, and automate the steps required to release the user’s software. A developer can quickly model and configure the different stages of a software release process. AWS CodePipeline automates the steps required to release the user’s software changes continuously.
HOW TO GET STARTED WITH AWS CODEPIPELINE
AWS CodePipeline is a continuous delivery service you can use to model, visualize, and automate the steps required to release the user’s software. A developer can quickly model and configure the different stages of a software release process. AWS CodePipeline automates the steps required to release the user’s software changes continuously.
Continuous Delivery and Integration with AWS CodePipeline
AWS CodePipeline is a continuous delivery service that automates the building, testing, and deployment of the user’s software into production.
Continuous delivery is a software development methodology where the release process is automated. Every software change is automatically built, tested, and deployed to production. Before the final push to production, a developer, an automated test, or a business rule decides when the final push should occur. Though every successful software change can be immediately released to production with continuous delivery, not all changes need to be released immediately.
Continuous integration is a software development practice where team members use a version control system and integrate their work frequently to the same location, such as a master branch. Each change is built and verified by means of tests and other verifications in order to detect any integration errors as speedily as possible. Continuous integration is focused on automatically building and testing code, as compared to continuous delivery, which automates the entire software release process up to production.
HOW ACTUALLY THE AWS CODEPIPELINE WORKS?
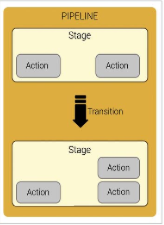
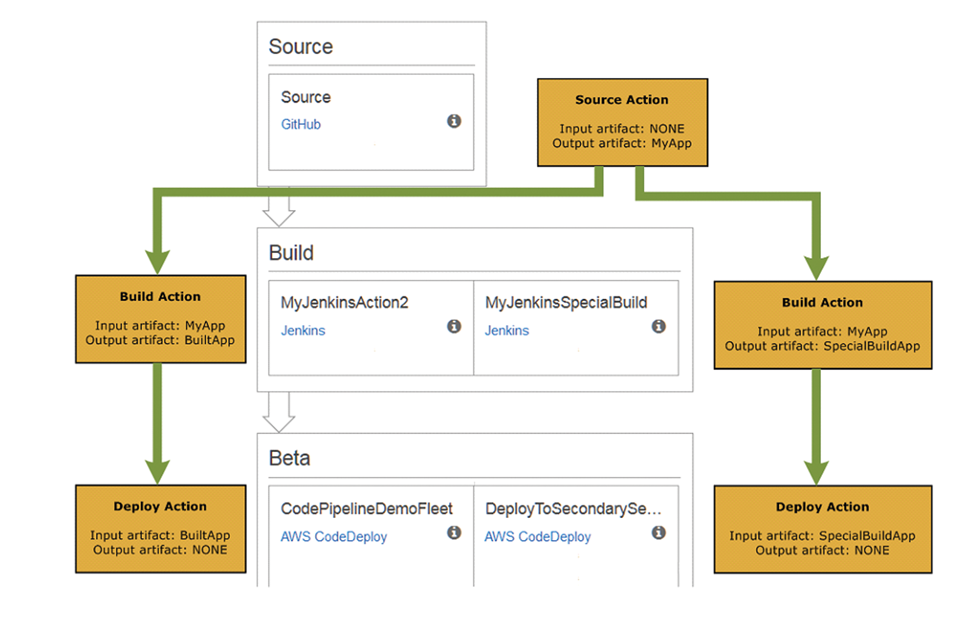
AWS CodePipeline helps the user to create and manage their release process workflow with pipelines. A pipeline is a workflow construct which describes how software changes go through a release process. A user can create as many pipelines as they need within the limits of AWS and AWS CodePipeline, as described in Limits.
The following diagram and accompanying descriptions introduce you to some of the terms unique to AWS CodePipeline and how these concepts relate to each other:
When the user creates the first pipeline using the console, AWS CodePipeline creates a single Amazon S3 bucket in the same region as the pipeline to store items for all pipelines in that region associated with the user’s account. Every time the user creates another pipeline within that region in the console, AWS CodePipeline creates a folder in that bucket for that pipeline and uses that folder to store artifacts for the user’s pipeline as the automated release process runs. This bucket is named as codepipeline-region-1234567EXAMPLE, where a region is the AWS region in which the user creates the pipeline, and 1234567EXAMPLE is a ten-digit random number that ensures the bucket name is unique.
If the user creates a pipeline using the AWS CLI, the user can choose any Amazon S3 bucket to store the artifacts for that pipeline, as long as that bucket is in the same region as the pipeline.
AWS CodePipeline breaks up the workflow into a series of stages. For instance, there might be a build stage, where the code is built and tests are run. There are also deployment stages, where code updates are deployed to run-time environments. The user can configure multiple parallel deployments to different environments in the same deployment stage. Also, the user can label each stage in the release process for better tracking, control, and reporting.
Every stage contains at least one action, which is some kind of task performed on the artifact in that stage. Pipeline actions occur in a specified order or in sequence, as determined in the configuration of the stage. For instance, a beta stage might contain a deploy action, which deploys code to one or more staging servers. You can configure a stage with a single action to start, and then add additional actions to that stage as needed.
RUNNING A PIPELINE
A pipeline starts automatically as soon as it is created. The pipeline might go to pause while waiting for the events, such as the start of the next action in a sequence, but it is still running. When the pipeline completes the processing of a revision, it will wait until the next revision occurs in a source location as defined in the pipeline. As soon as a change is identified in a source location, the pipeline will begin running it through its stages and actions.
The user cannot manually stop a pipeline after it has been created, but you can disable transitions between stages to prevent stages and actions from running or adding an approval action to the pipeline to pause the execution until the action is manually approved. To assure a pipeline does not run, the user can also delete a pipeline or edit the actions in a source stage to point to a source location where no changes are being made. If the user deletes a pipeline for this purpose, make sure that a developer should have a copy of its JSON structure first. That way the developer can easily restore the pipeline when they want to re-create it.
CanJS is a lightweight, modern JavaScript MVVM (Model-View-View-Model) framework which is quick and easy to use while remaining robust and extensible to power some of the most trafficked websites in the world. This article will walk you through about CanJS and why you should use CanJS.
GET STARTED WITH CANJS
CanJS is a developing and improving set of client-side JavaScript architectural libraries which balances innovation and stability. It targets experienced developers, building complex applications with long future ahead. CanJS’s major aim is to reduce the cost of building and maintaining JavaScript applications by balancing innovation and stability, helping the developers to achieve a changing technology landscape.
The developer shouldn’t have to rewrite the application to keep pace with technology. CanJS aims to provide a stable and innovative platform, so the developer can block out the noise and stay focused on their applications, but not on the tools.
EVERY CANJS APPLICATION CONTAINS
Observables
Models
ViewModels
Views
Custom elements and
Routing with an AppViewModel
OBSERVABLES
Observable objects provide a way for the developer to make changes to the data. Observables such as can.The list, can.Map, and can.compute provides the foundation for models, view-models, view bindings, and also for routing in the developer’s app. can.compute is able to combine observable values into new observable values.
var info = can.compute(function(){
return person.attr(“first”)+” “+person.attr(“last”)+
” likes “+ hobbies.join(“, “)+”.”;
}); MODELS
Models let the developer to modify the data from the server. They also hydrate raw, serialized service data into more useful (and observable) type data on the client side. can.Model makes it easy to connect to restful services and perform Create, Retrieve, Update, and Delete the operations.
VIEWMODELS
ViewModels contains the state and model data used by the views to create HTML. They also contain methods that views can call.
VIEWS
Views are passed to a view-model and generate a visual output that’s meaningful to a user. Views are able to:
Listen to the changes in view-models and update the HTML (one-way bindings).
Listen to the HTML events, such as clicks, and call methods on the view-models and models (event bindings).
Listen to the form elements changing and update view-model and model data (two-way bindings).
CUSTOM ELEMENTS
Custom HTML Elements are for how CanJS encapsulates and orchestrates different pieces of functionality within an application. Custom elements are built with the can.Component and combines a view-model and view.
ROUTING WITH AN APPVIEWMODEL
CanJS maintains a reciprocal relationship between the browser’s URL and a can.Map view-model. This view-model represents the state of the application as a whole and so is called the appViewModel. When the URL changes, CanJS will update the properties of the appViewModel. When the appViewModel changes, CanJS will update the URL.
WHY CANJS?
CanJS is designed to be a very well-rounded JavaScript framework which is useful to any client-side JavaScript team.
It provides a wealth of JavaScript utilities that combines to make a testable and repeatable Model-View-ViewModel application with very little code.
FLEXIBLE
CanJS is flexible. Unlike other frameworks, it’s designed to work in any situation. The developer can readily use third party plugins to modify the DOM with jQuery directly and uses alternate DOM libraries like Zepto and Dojo. CanJS supports all the browsers including IE8.
POWERFUL
CanJS is powerful. It creates the custom elements with one and two-way bindings. It easily defines the behavior of observable objects and their derived values. It avoids memory leaks with smart model stores and smart event binding.
SIMPLE EXAMPLE OF CANJS
The below code explains a simple template with events.
When we talk about parallel programming, typically we are always interested in decreasing the execution time by taking the advantage of hardware’s ability to do more than one job at a time, whether by vectorization, instruction-level parallelism or by multiprocessing. Parallel programming does not implicit a particular programming model, and many techniques and languages for parallel programming are at various stages of development or adoption.
One model which seems to be promising is data parallelism, in which uniform operations over aggregate data can be sped up by dividing the data and computing into the partitions simultaneously. For instance, High-Performance Fortran offers parallel loops, where an operation such as adding up two arrays element-wise can be sped up by vectorizing a loop or splitting it between several processing units that handle different portions of the arrays simultaneously. Data Parallel Haskell, a research language, expands this model to allow parallelizing operations on ragged arrays of arrays. The best thing about data parallelism is that it’s usually deterministic and implicit— the user does not have to write a program that says “do these four things at the same time,” but rather say “do this to that whole array” and the compiler or run-time system works on how to partition things. The less admirable thing is that data parallelism usually only applies when the user has a big array that you want to treat more or less uniformly.
Another approach of parallelism is futures or fork/join parallelism, in which some computations whose value is not needed right away is started in parallel with the “main” computation, and then when the main computation needs the result of the side computation, it may have to wait till it is finished. An expression e could instead be written (FUTURE e), and it would mean the same thing, but might run in parallel until its value is actually needed. The other language that provides a similar model is Cilk, a C-like language that has a parallel procedure call mechanism that looks a lot similar to futures. Futures are often good when the user have a computation that can be broken into pieces whose values depend on each other in well-defined ways but aren’t necessarily uniform enough for data parallelism to work.
CONCURRENT PROGRAMMING
In concurrent programming, a program is typically factored into multiple threads of control with clear responsibilities and purposes, which may run simultaneously or take turns. This is often about dealing with concurrency and nondeterminism in the world, or about reducing latency. For instance, the user’s web browser needs to deal with events from the UI and events from the network while also performing some computation such as rendering a page. While it is possible to program as a single thread of control that checks for various events and does other computations, it’s often easier, conceptually, to think of it as several different processes cooperating on different aspects of the whole.
Most of the programming models for concurrency differ along two main axes: how processes are scheduled and how they cooperate. For the former, one end of the axis is pre-emptive multithreading, wherein several independent instruction streams run either simultaneously on different execution units or are given turns by a scheduler. This is the scheduling model used by Java and pthreads. At the other end are co-routines, which yield control to one other at well-defined points of the programmer’s choosing. This is the main idea behind Ruby’s fibers. Other models for scheduling include event loops with call-backs, as used by some GUI libraries, and stream transducers in data flow programming. One advantage of pre-emptive multithreading is that it can reduce latency, and it doesn’t require programmer effort to figure out when to transfer control, but a big disadvantage is that it can make the coordination more difficult.
Coordination—how multiple threads of control cooperate to get something done. Probably the most common model, and the hardest to use is shared memory with explicit synchronization. This is the model used by pthreads and, to some extent, Java. In this model, mutable objects may be shared by multiple threads running at the same time, which is a common source of bugs. Synchronization mechanisms such as locks can prevent interference, but they introduce problems of their own. Java improves on this model a bit with monitors, which make some synchronization less explicit, but it’s still pretty difficult to get right.
Because of the problems with shared-memory concurrency, two other models for concurrent communication have been achieving traction lately: transactional memory and message passing. In a transactional memory system, memory appears to be shared between threads, but it provides atomic transactions, whereby a thread may make several accesses to shared mutable variables and have guaranteed isolation. This has been implemented in software, originally in Concurrent Haskell, and latterly in other languages such as Clojure. In message-passing concurrency, threads no longer share mutable variables but communicate explicitly by sending messages. The poster language for message-passing concurrency is Erlang, and another language with a slightly different approach is Concurrent ML.
FINAL CONCLUSION
In this article all that we explained is the most modern programming languages support both concurrency and parallelism, through multiple paradigms. For instance, C#’s native model for concurrency is shared memory with synchronization, but there are libraries for both message passing and software transactional memory. In some sense, shared memory is the least-common-denominator on which other concurrency approaches and parallelism may be implemented. Many programs can benefit from both parallelism and concurrency. For example, the web browser may be able to speed up particular tasks, such as rendering, by parallelizing them, at the same time that it uses concurrency to deal with concurrency in the world.
Amazon Elasticsearch Service (Amazon ES) is a managed service that makes it easy to create a domain, deploy, operate, and scale Elasticsearch clusters in the AWS Cloud.
Features:
Security with AWS Identity and Access Management (IAM) access control
Dedicated master nodes to improve cluster stability
Domain snapshots to back up and restore Amazon ES domains and replicate domains across Avail ability Zones
Data visualization using the Kibana tool
Integration with Amazon CloudWatch for monitoring Amazon ES domain metrics
Integration with AWS CloudTrail for auditing configuration API calls to Amazon ES domains