
Kubernetes with Flannel
Kubernetes is an excellent tool for handling containerized applications at scale. But as you may know, working with kubernetes is not an easy road, mainly the backend networking implementation. Many developers have met many problems in networking and it costs much time to figure out how it works.
In this article, we want to use the simplest implementation as an example, to explain kubernetes networking works. So, let’s dive deep!
KUBERNETES NETWORKING MODEL
Kubernetes manages a cluster of Linux machines, on each host machine, kubernetes runs any number of Pods, in each Pod there can be any number of containers. User’s application will be running in one of those containers.
For kubernetes, Pod is the least management unit, and all containers inside one Pod shares the same network namespace, which means they have same network interface and can connect each other by using localhost.
KUBERNETES NETWORKING MODEL NECESSITATES
All containers can communicate with all other containers without NAT.
All nodes can communicate with all containers without NAT.
The user can replace all containers to Pods in above requirements, as containers share with Pod network.
Basically it means all Pods should be able to easily communicate with any other Pods in the cluster, even they are in different Hosts, and they recognized each other with their own IP address, just as the underlying Host does not exists. Also the Host should also be able to connect with any Pod with its own IP address, without any address translation.
THE OVERLAY NETWORK
Flannel is created by CoreOS for Kubernetes networking, it can also be used as a general software defined network solution for other purpose.
To achieve kubernetes network requirements, create flat network which runs above the host network, this is called overlay network. All containers(Pod) will be assigned one IP address in overlay network, they communicate with each other by calling each other’s IP address directly.
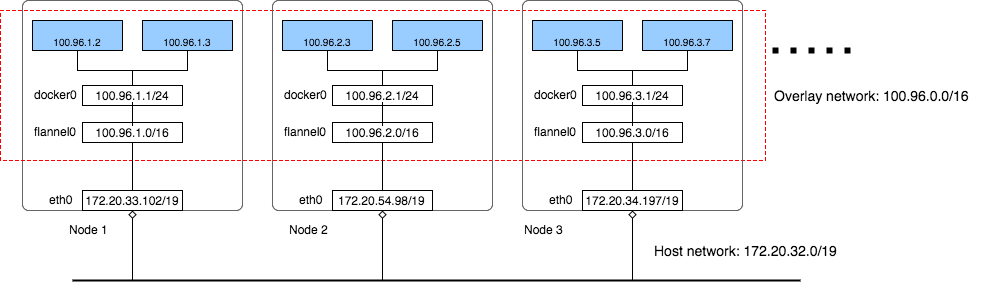
In the above cluster there are three networks:
AWS VPC Network: All instances are in one VPC subnet 172.20.32.0/19. They have been allocated IP addresses in this range, all hosts can connect to each other because they are in same LAN.
Flannel overlay network: Flannel has created another network 100.96.0.0/16, it is a bigger network which can hold 216 (65536) addresses, and it is across all kubernetes nodes, each pod will be assigned one address in this range.
In-Host docker network: Inside each host, flannel assigned a 100.96.x.0/24 network to all pods in this host, it can hold 28 (256) addresses. The Docker bridge interface docker0 will use this network to create new containers.
By the above design, each container has its own IP address, all fall into the overlay subnet 100.96.0.0/16. The containers inside the same host can connect with each other by the Docker bridge docker0. To connect across hosts with other containers in the overlay network, flannel uses kernel route table and UDP encapsulation to attain it.
PACKET COPY AND PERFORMANCE
The newer version of flannel does not recommend to use UDP encapsulation for production, it should be only used for debugging and testing purpose. One reason is the performance.
Though the flannel0 TUN device provides a simple way to get and send packet through the kernel, it has a performance penalty, the packet has to be copied back and forth from the user space to kernel space.
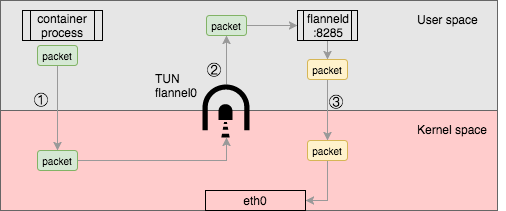
as the above, from the original container process send packet, it has to be copied three times between user space and kernel space, this will upsurge network overhead in a significant way.
THE VERDICT
Flannel is one of the simplest implementation of kubernetes network model. It uses the standing Docker bridge network and an extra Tun device with a daemon process to do UDP encapsulation. We hope this article helps you to understand the fundamentals of kuberentes networking, with this information you can start exploring the more interesting realm of kubernetes networking.
